UPDATE: The contents of this post are still valid, but there is a new, complementary post: How to Match to Weibull Distribution without Excel.
Warning: this is a very technical, hands-on post.

Weibull distribution
It turns out Weibull distribution is quite common among statistical distributions of lead times in software development and IT projects. This insight belongs to Troy Magennis, who is a leading expert on Monte Carlo simulations of projects and examined many data sets from real-world projects. He also has an explanation how the nature of knowledge work and its tendency to expand and get interrupted leads to this distribution. I recommend that you learn more about his work that won him a Brickell Key Award. The insight about Weibull distribution has been confirmed independently by another Brickell Key winner Richard Hensley who has examined many data sets from the IT organization of a large company.
Do Your Lead Times Match Weibull Distribution?
I had to come up with a quick answer to this question yesterday, using only my understanding of statistics and Excel. Weibull distribution is actually a family of distributions, parametrized by the so-called shape parameter (k). You can see in the chart above how changing this parameter can tweak the shape of the distribution curve. Weibull is identical to the exponential distribution when k=1, to Rayleigh distribution when k=2, and interpolates/extrapolates those distributions for other values of the parameter. So we have two questions to answer here:
- Does a given set of numbers match Weibull distribution?
- If it does, what is its shape parameter?
Here is a simple algorithm you can follow to answer these questions for your data set. I’ll attach the spreadsheet at the end of this post.
Step 1. Copy and paste your numbers in to column A of the spreadsheet. I prefer to reserve Row 1 for column headers, so the numbers will start from the cell A2.
Step 2. Sort the numbers in column A in the ascending order.
Step 3. Divide the interval [0; 1] into as many equal intervals as you have data points in your set and populate column B with centers of those intervals. If you have N=100 data points, the Excel formula for this is =(2*ROW(B2)-3)/200 (200 == 2*N). Type this formula into the cell B2 and copy and paste it to fill all cells in Column B.
Step 4. Populate Column C with natural logarithms of numbers in Column A. Type =LN(A2) into the cell C2, copy and paste the formula to the rest of Column C.
Step 5. Populate Column D with the numbers calculated from Column B as follows. Type =LN(-LN(1-B2)) into the cell D2, copy and paste to the rest of Column D. We’re basically linearizing the cumulative distribution function here so that linear regression can reveal the shape parameter.
Step 6. If the set matches Weibull distribution, then the shape parameter is the slope of the straight line through the set of points with the coordinates given by numbers in Columns C and D. Calculate it using this formula: =SLOPE(D2:D101,C2:C101) (This assumes your set contains N=100 points, adjust the formula accordingly). In the attached spreadsheet, this number is placed into the cell G2.
Step 7. Calculate the intercept: =INTERCEPT(D2:101,C2:C101). (Cell G3.)
Step 8. Calculate the scale parameter from the intercept: =EXP(-G3/G2). (Cell G4.)
Step 9. Test how good the fit is by calculating the R-squared: =RSQ(C2:C101,D2:D101). If the match is perfect, this number will be equal to 1.
Step 10. If we have good fit, we can also do a simple sanity check and calculate the mean from the newly obtained shape and scale parameters and see if it is close enough to the actual mean. The formula for the mean is
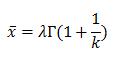
The standard Excel doesn’t have built-in Gamma-function, but has a built-in function that returns its logarithm. So, we can calculate the predicted mean by =G4*EXP(GAMMALN(1+1/G2)). Now you can compare the predicted mean to the actual mean, which can be obtained, of course, by =AVERAGE(A2:A101).
UPDATE
There is more than one way to do linear regression. The above steps will minimize the vertical distances (in the y-axis direction) between the best fit curve and the data points. It is also possible to do it by minimizing the horizontal distances. The latter method consistently overestimates the shape parameter, which is undesirable for the practical applications of lead time analytics, and can be inaccurate if the same number occurs in the data set multiple times, especially on the left side of the distribution. For these reasons, I don’t recommend using this method and instead recommend the method I originally described in the steps above (linear regression, minimizing vertical distances).
I’m also updating the Weibull Distribution Fit spreadsheet with “smarter” formulas. You don’t need to adjust the above formulas depending on the number of data points in your lead time set.






Great post, Alex! A couple of questions: What can we infer from the different Weibull Distribution shapes with respect to lead times, and for that matter how do we define “lead time” vs. “cycle time” with respect to Magennis and Hensley’s work?
Chris, the definitions of cycle and lead time is orthogonal to this problem. We can take a set of cycle times, however that is defined, see if it matches the distribtion, and repeat for any set of numbers.
What I’m hearing regarding the shapes is that Weibull-distributed sets from software and IT projects have shape parameters within a certain range. This is why the distinct asymmetric fat-tailed shape is often drawn in the software/IT context even though not all Weibull distribution curves look like that. Knowing what the shape range is would help us come up with simple methods to be used as rules of thumb to calculate control limits, confidence intervals, etc. That would be a good topic for a future post.
Love this approach. I use off the shelf tools, but knowing and understanding how they work is an excellent skill.
I’ve found some pre processing required before matching data to any distribution. Here are some things I look for and do, but would love to hear what others do –
1. Zero values: A lot of electronic systems calculate cycle time by subtracting end date from start date. This gives zero for state changes occurring on the same day. I often change these to 0.5 days.
2. Lots of high end outliers of the same value. Often work items imported from old systems are imported at one date and not completed. I have always found some high end outliers that aren’t typical cycle time. I tend to investigate a few and delete them if they are truly not valid samples.
3. Multi-modal. Sometimes there is a significant cluster around certain values making the histogram of that data multi-modal (two or more peaks). I look at a few of these samples to determine if those samples, or which grouping is more like the work to be forecasted. I sometimes split these samples into two groups to keep in my “library” of samples and use the correct samples for future projects depending on the type of work.
Troy
Troy, thank you for this comment. Great advice on pre-processing data from tools.
Regarding multi-modal sets, I left it out of the scope of this particular post, but actually had to do this analysis at work on the same day. This set has four modes in it (somewhat different types of projects), with different averages. Two of them were close to Weibull, but two others were “unique” distributions..
Pingback: The Best of 2013 | Learning Agile and Lean
Pingback: Analyzing the Lead Time Distribution Chart | Connected Knowledge
Pingback: How to Match to Weibull Distribution without Excel | Connected Knowledge
Pingback: The Best of 2014 | Connected Knowledge
What would be a default value (range?) for k that I can use to estimate fixed priced IT projects.
Currently I am decomposing business functions in activities for which I do a three point estimate using Fibonacci numbers. I calculate direct and indirect costs (times) using historical data.
then we use normal distribution to estimate risks and would like to replace the model with a Weibull distribution. What would be a good model I can start with as a first try (K=?)? Thanks.
Alex, sorry for the long delay. I kind of neglected the blog for the last couple of months.
The simple answer about the Weibull shape parameter (k) is this. For most product development activities, you can assume k=1.5 if you know nothing about the process. In real-time processes such as technical support and customer care k=1 is more typical and k2 (important: one point in such lead time data set is one large project).
However, the rest of your comment is quite strange. Why would you ask me this question if you already had historical data? You could just find the answer from your own data!
Your mention of Fibonacci numbers suggests you may be trying to estimate effort. However, if your objective is to manage schedule risks, the relevant metric is the lead time. And, as research of data sets from real-world processes shows, the two have almost no correlation. This is to be expected when the flow efficiency of the delivery process is low. It is indeed low enough (below 5%) in most delivery processes in knowledge work, including IT.
Thanks a lot for your answer. I do have historical data but it is not structured so it is hard to draw conclusions from it.
@Alex, if you were measuring the lead time of things that make up your projects, then that would be very easy. You must be measuring something else.
Alexei,
We were measuring the lead time, but the activities were not broken down based on any specific criteria. We did not do any function point analysis for example to understand the correlation between that and the time spent on an activity. Some activities were a few hours long, some were a few days or weeks long. I don’t think such a spread could give one any feedback about how long an activity would take!
Lately we have introduced some standardization (not sure this is the proper word!?) to try to break the activities up into more manageable units but not everyone is following this rule.
@Alex, ok, I got it. You described something very common: a wide range of possibilities on a lead-time distribution. You have to deliver a project – a batch of N features – and each of them has this sort of predictability. If N is large enough, outliers (90th percentile and up) will materialize Yes, this is a big challenge in project/release planning. Yes, if you can find some improvements, for example, “trim the tail” of the distribution or drill it down by work item type, the distributions will be less dispersed and planning projects/releases will get easier. This is why it’s very important to pay attention to the feature-level flow, understand and continuously improve it (here I use the word “feature” to mean smaller things that the big things-projects are made of).
The topic of planning a project using Kanban metrics is big enough for at least one whole blog post. So, I’ll only comment on how this distribution can be used during the project. It provides important and tight feedback loops. The median of the distribution is left-shifted, occurs very early. (1) Half of the features should be delivered in less time. You will know quickly if this is not the case. (2) Pick a control limit (high percentile, e.g. 90% and up) – you should see very few features with longer lead times as the project progresses. If the conditions (1) and (2) are not met, your project plan was too optimistic and these feedback loops tell you the project is off the track before it actually gets off the track. If the conditions are met, your project is on track. If the delivery is faster than these conditions, then you have realized some process improvement and gained some margin of safety.
Thank you!
Hey azheglov,
Thank you for the article.
Is it possible you could explain the expression in step 5 to me? ‘=LN(-LN(1-B2))’
Where did you derive this from?
Hello Christian,
As the comment to step 5 says, we’re basically linearizing the cumulative distribution function.
The formula for Weibull CDF is F(x) = 1-exp(-(x/lambda)^k). After a few simple algebraic manipulations, this equation transforms into:
ln(-ln(1-F(x))) = k * ln(x) – k * ln(lambda)
This enables us to estimate the distribution parameters k and lambda by correlating ln(x) versus ln(-ln(1-F(x))).
Thank you for clarifying! 🙂
I am currently investigating wind speeds on a site for a wind turbine (at my home).
So I estimated the k and lambda values with your method. Then sorted all the data points i measured into bins in excel. And then I assume I can use the same estimated k and lambda values to calculate the weibull probability density function in excel? (And from there the power in the wind).
Would that be correct?
Hey, azhgelov,
Would you please explain how you derived the function ‘=LN(-LN(1-B2))’ in Step 5?
@Christian,
Although I’m not an expert in wind power, I suspect you can probably calculate the total power output from your wind turbine using the actual wind measurement data points you already have. Parametrized theoretical distributions are there primarily to understand the nature of the statistical phenomenon you’re looking at.
Would you mind sharing what parameters k and lambda you got or sending me your array of data privately at alex@LeanAtoZ.com?
Thank you.
I send you an email.
Alexei,
How did you arrive at using “=(2*ROW(B2)-3)/200 (200 == 2*N)” for determining your median rank? This yields different results than Benard’s equation or Excel’s exact function BETAINV. Just curious. Thanks.
This formula simply computes 100 evenly spaced numbers fitting into the [0, 1] interval so that I don’t have to type them manually. A later version of this workbook has a more flexible formula in case N is not equal to 100.
Pingback: Как сверить выборку с распределением Вейбулла в Excel | Kanban Russia