There is a general trend and desire to make work more collaborative. Yet when I ask groups of people in the workplace to draw a diagram of how they work, they often come up with something like this (I’m simplifying it):
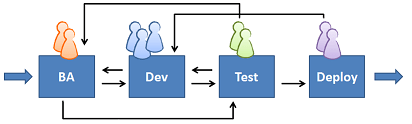
In this view, the workers form an assembly line. But their work doesn’t really flow like an assembly line. For example, a Software Developer may find a logical inconsistency in a feature specification and send the work back to a Business Analyst. A Quality Assurance specialist may do the same when testing the implemented software. The BA will update the spec and send the work back to QA. QA may find a bug in it and send the work back to the Developer. The Deployment Specialist may find something in the code to be an impediment to deployment. The Developer then makes the necessary change. The code now needs retesting, so it goes back to QA, after which it goes again to Deployment.
Such back-and-forth occurs not only between individuals, but also, importantly, between corporate departments, services and cross-functional teams. So people draw many arrows going back and forth between them to show all these handoffs.
Some try to visualize this process on a board they call “kanban”:
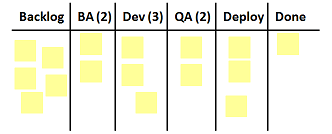
Then they ask, what if, for example, testing hands the work back to BA or Dev? Should the card stay in its place or move? What if we have WIP limits? (Those numbers in the column captions.) What if that column is already filled up to the limit and another card needs to move back?
Is There a Better Way?
This question is fairly common and rooted in the misunderstanding of the nature of professional-service work. Rather than a series of handoffs between specialist workstations, it is mostly about creating information and knowledge. It may be limiting to try to make such process look like a block-diagram. It may be limiting to try to visualize it by following the work.
In the example of product feature delivery, the following knowledge may get created, not necessarily in this order:
- the exact configuration of the production environment (OS, Web server, database server, third-party software)
- key examples of how the product feature will behave, use cases, acceptance criteria, executable specifications, etc.
- how to integrate the new feature with the pre-existing product functionality (upgrade procedures, data migration, etc.)
- what will the design and implementation exactly look like
- what tests are needed to support the implementation
- how the updated product behaves with respect to its performance and other quality (non-functional) requirements
- results of usability tests and exploratory testing sessions
- what else users need to use the updated product: customizations, training, localization, etc.
- etc.
Anyone in any professional service field can come up with their own list of knowledge they create in their own delivery process. When the work is complete, all of such knowledge is there. But when we only get started working on a customer need or a request to deliver something, it is not there yet.
If we tried to visualize the process of accumulating this knowledge, the result could look like this:
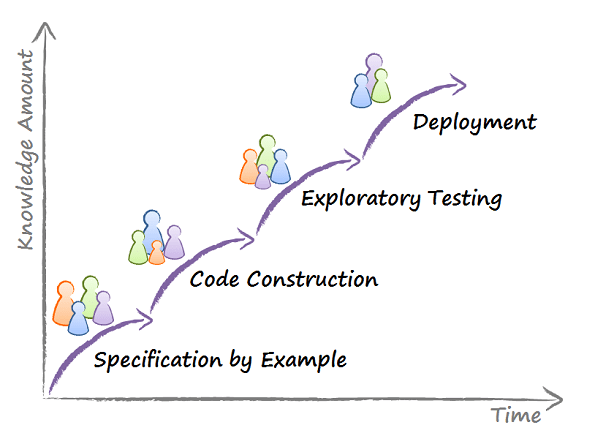
In this example, specification activities dominate the early phase of the delivery process. The Business Analysts may lead the analysis of the feature, decomposition, fleshing out requirements. But other specialists can contribute at the same time. Testers may help turn acceptance criteria in to (executable) tests. Deployment specialists and Developers may weigh in on what may have what impact on the codebase and infrastructure.
This activity produces a lot of knowledge from the start, but it fades eventually. We can’t analyze our way to delivery. So, code construction becomes at some point the main way to accumulate knowledge.
A lot of code construction falls on Developers’ shoulders, of course. But others can help, too. Requirements may still need refinement and clarification (hello BAs). A Tester may take the partly finished software, test it and give feedback to a Developer. Developers can collaborate with Deployment specialists to see how the emerging code changes may impact deployment.
But this activity will fade too. We can’t make further progress by polishing the code. So, we switch to testing it and focusing on getting any remaining bugs out. Another knowledge-creating activity begins to dominate. Testers lead it, but they get help from Developers fixing bugs, and others as well.
Note that the three inflection points in the new process diagram are not handoffs between functional specialists or departments. They are changes of the dominant activity and the corresponding shifts in the collaboration pattern.
Conclusion
We don’t have to look at processes as networks of specialists and handoffs. When trying to understand our processes visually, we don’t have to diagram them as boxes depicting the specialists and many arrows connecting them every which way.
We can instead consider our delivery process to be about information arrival and knowledge creation. By asking ourselves, what activities do we perform to discover knowledge to deliver what we are delivering, we can visualize our process as a sequence of collaborative activities.
What’s Next
In the next several posts, I would like to give some examples of such Knowledge Discovery Process maps, mostly for processes outside the world of software delivery (UPDATE: I’ve posted two such examples, in addition to the software development process example above. One example is from the field of entrepreneurship/lean startup and one from training and courseware).
I also need a series of posts to give guidance on how a process coach can go about mapping such processes with real teams of professionals. For those using kanban systems, this approach has some implications for how to design and operate those systems.






Pingback: KDP Example #1: A Startup’s Measure-Learn Process | Learning Agile and Lean
Pingback: KDP Example #2: Training and Courseware | Learning Agile and Lean
Hi Alexi,
This is great that you are tackling this area. I am currently reading the 2nd edition of Allen C Ward’s book, Lean Product and Process Development, http://www.lean.org/Bookstore/ProductDetails.cfm?SelectedProductId=383 – I highly recommend it. In it he asserts and shows that product development is a knowledge creation activity and that handoffs are its biggest waste. And once created knowledge needs to be encoded so that it can be reused in building new products or alternate versions of existing ones – he refers to “trade-off curves” as one of the best ways of doing this. Like you, he recognized that part of the task of doing product development is creating the process that supports the creation of the knowledge needed to do that particular product development and that without the right process you will not get the right product, except by luck, i.e. people do win lotteries.
There is an interesting argument that could be made that this lack of focus on knowledge creation and reuse is the single biggest systemic problem with Agile practices and methodologies world-wide and that this is, in Jungian terms, the “shadow” of the Agile Manifesto. 😉
Norbert,
Thank you for the comment. I should add Allen C. Ward’s book to my backlog. 😉
What I wrote about here is not original. But I often meet people who wish there was more practical guidance. I can give them that from my own experience. But the problem is, it is mostly not written down anywhere. I’m trying to fix that.
Alexi,
Your welcome and yes you should, it is a great book. 🙂
As to the originality part, I like this letter from Mark Twain to Helen Keller on originality: http://is.gd/5UYUWn. Your summary and interpretation of what you have learned is original and based on my interactions this is big problem that most people are not directly aware of and so contribution helps, keep it up.
Pingback: Mapping Your Process as Collaborative Knowledge Discovery – Part 1 (Recipes) | Connected Knowledge
Pingback: Mapping Your Process as Collaborative Knowledge Discovery – Part 2 (Observations) | Connected Knowledge
Pingback: Mapping Your Process as Collaborative Knowledge Discovery – Part 3 (Thinking) | Connected Knowledge
Pingback: #BeyondVSM: Understanding and Mapping Your Process of Knowledge Discovery | Connected Knowledge
Pingback: The Best of 2014 | Connected Knowledge
Pingback: Knowledge Discovery Process Revisited | Connected Knowledge
Pingback: Понимание вашего процесса как процесса коллективного накопления знаний | Kanban Russia
Pingback: Понимание вашего процесса как процесса Коллективного накопления знаний – Часть 1 (рецепты) | Kanban Russia
Pingback: Канбан метод: Понимание вашего процесса как процесса Коллективного накопления знаний – Часть 1 (рецепты) / Хабр
Pingback: Визуализация работы. Часть 2. Делаем рабочий процесс видимым