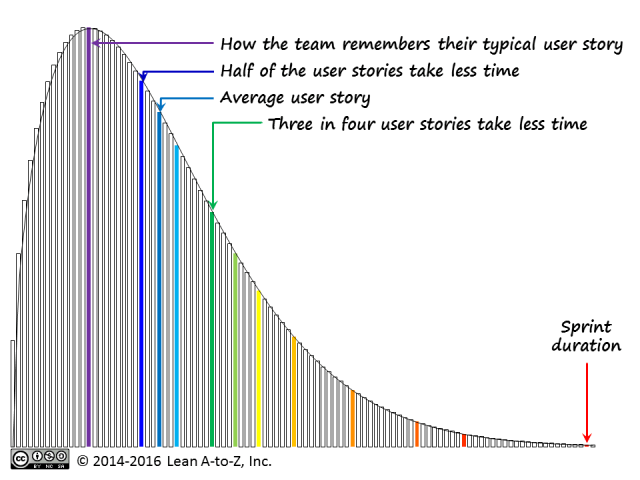
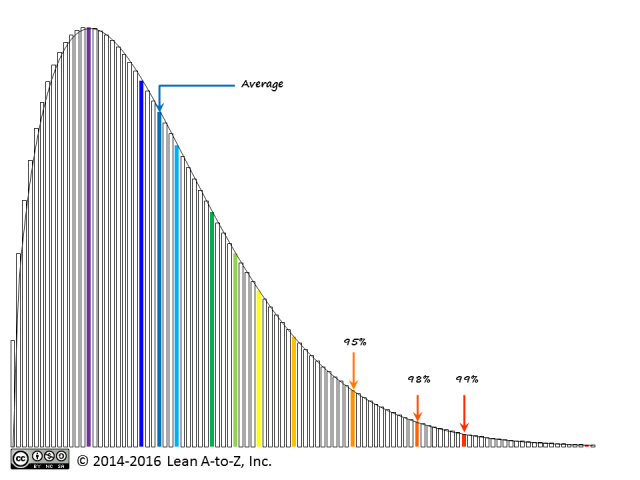
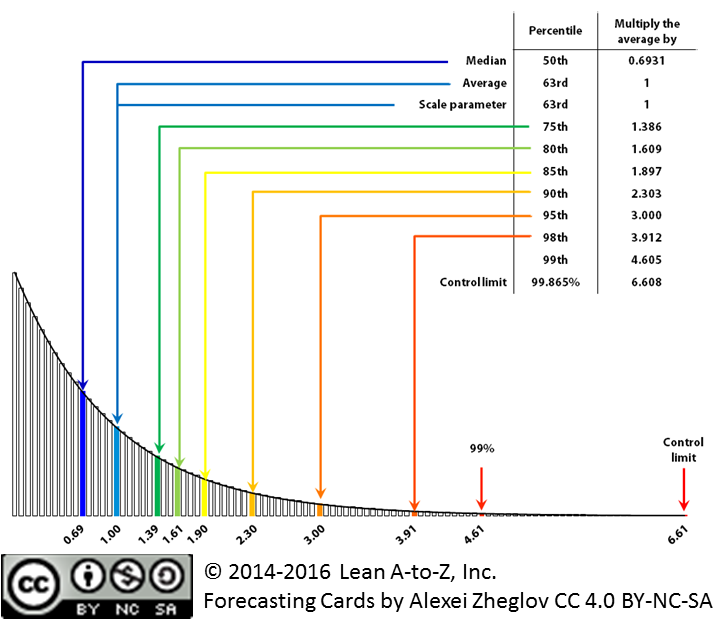
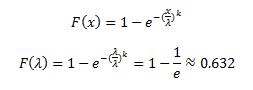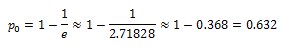The cycle time has been a hot topic for me lately. A debate is going on on kanbandev.
Meanwhile, someone at a client site has asked my advice on continuous delivery (of software) and whether “the cycle time” is a useful metric for it based on some article they found somewhere on the Internet and read over the weekend. The article was written purely at the practice level, without context and the author assumed whatever cycle time meant to them was “the cycle time” and didn’t bother with any definitions. That was a lot to sort out.
There is no such thing as “the cycle time”
It is an overloaded term and its uses should always be qualified.
In the manufacturing domain, where there is a stable definition of cycle time and where the term can be used without qualifiers, it means something very different from how the author used the term. It means the (average) interval between successive deliveries. For example, if the cycle time of a car assembly line is 45 seconds that means, on average, every 45 seconds a new car rolls off (actually, at nearly perfect 45-second intervals, because there is very little variability in the manufacturing process). A total of 60 * 60 / 45 = 80 cars are produced every hour. (Note that the lead time to manufacture a car is significantly longer than 45 seconds.)
If we’re to adopt this definition in the software development domain, the cycle time means the reciprocal of the deployment frequency. For example, if a team demoes their user stories every two weeks, but actually ships only after multiple increments are integrated into a six- month release plan, then their cycle time is 6 months. If they ship at the end of every sprint, then their cycle time is 2 weeks. If they deploy 50 times a day on average, their average cycle time is approximately 29 minutes. The average cycle time of the software delivery process at Amazon is reportedly 11 seconds.
The Software G-Forces
Kent Beck, one of the eXtreme Programming pioneers, proposed a model called the Software G-Forces. He showed the scale of deployment frequencies (cycle times), from yearly to quarterly to monthly to weekly to daily to hourly or less. He also showed how the distribution of where software companies fit on this scale changed over time. There are no best practices for delivery. Whatever the practices you’ve got are the right practices for delivering at the frequency you’ve got.
Speaking in terms of delivery frequency also avoids the terminological overload of “cycle time.”
Cycle time and continuous delivery
Beck further contends that if you want to double or triple your frequency, doing so will likely break your existing process. You have to figure out which new practices to add to your process and which practices to part with. Addition and subtraction of practices will always be contextual. For example:
- Delivering once in 6 months may involve little test automation, but, if you want to deliver every 2-3 months, you will probably need to invest in test automation. The full manual regression test may take too long.
- Going from once every few months to once every few weeks is likely to require automated provisioning of various testing, staging, certification and production environments. “Snowflake” servers may stand in the way.
- Delivering once a two-week sprint or more frequently generally requires a properly designed, unit-testable code base with good amount of unit test coverage. Are all developers fluent in SOLID principles? There will be no trivial bugs for testers to catch – are they trained in exploratory testing?
- Delivering more frequently than once a week tends to break processes based on time-boxed frameworks.
- To deliver more than once a day, you may need to solve the bottlenecks in your deployment pipeline.
- And so on – you can easily turn this into a very long checklist of practices.
What about local cycle times?
Other uses of “cycle time” are possible in the software domain, but they all mean the time through a local activity (or a continuous sequence of activities) and all need to be qualified where they’re from and to (something the author neglected to do). As it turned out upon careful examination of the article still influencing my client, its author didn’t mean any of the above definitions. He meant the time from the code commit to seeing it in production. It was the local cycle time of the deployment pipeline. (In the Kanban method terminology, his clock started at the second commitment point.)
By optimizing the local cycle time of the deployment pipeline, the author was effectively solving the Problem #5 from the long list above. This immediately raised the question whether the Problem #5 was contextually relevant to my client. (The answer was, without giving away anything: to some teams, yes; to other teams, no.)
Conclusion
Back to the original question: is “the cycle time” useful metric to inform progress towards continuous delivery? Generally speaking, no, unless we can all agree on the definition, which is clearly not happening.
Meanwhile, using the delivery frequency can be much more productive you can avoid using it to rank your teams. Team A delivers once a month; Team B, once a day. Is Team B better than Team A? No. Is Team B working on what it will take to deliver three times a day? No, they’re just cranking out user stories? If so, that’s not so good. Is Team A working on what it will take to delivery every two weeks? If yes, great!
If you’re still looking for a best practice from this memo, here it is. It’s okay to deliver only twice a year out of a legacy codebase with mostly manual testing. It’s not OK to say, when we’ll rewrite this codebase in a few years, it will be more conducive to deployments at the end of each sprint. It is also not OK to say, we’re deploying every day and are far ahead of those dinosaurs and their twice-a-year deployments. Instead, it may be preferable that each team have a goal to deploy 2-3 times more frequently than they do now. The leaders can communicate and set such expectations with the teams.